Effective document management is essential for both individuals and enterprises in the current digital era. Nevertheless, document editing and modification can frequently be a laborious and time-consuming process. Fortunately, we can develop a Document Modifier Tool i.e. Excel to Word Automation using Python to simplify this procedure thanks to the capabilities of Python programming.
What is an Excel to Word Automation?
A Document Modifier Tool is a software application that automates the process of editing and modifying documents.
It allows users to replace specific keywords or placeholders in a document with data from an external source, such as an Excel spreadsheet.
This tool can save significant time and effort, especially when dealing with large volumes of documents.
Automating Editing and Modification:
Traditionally, when you need to make changes to multiple documents, you have to manually open each document, find and replace specific words or phrases, and then save the changes.
This process can be tedious and time-consuming, especially if you’re dealing with a large number of documents.
A Document Modifier Tool automates this process, allowing you to make bulk edits and modifications with just a few clicks.
Understanding the Code:
Let’s take a closer look at the Python code that powers our Document Modifier Tool. The code is divided into several functions, each serving a specific purpose:
- Merge PDFs: This function merges multiple PDF files into a single PDF document, simplifying document management.
- Preprocess String: This function preprocesses strings by removing punctuation and converting them to lowercase, making it easier to compare and manipulate text.
- Convert to PDF: This function converts Word documents to PDF format, ensuring compatibility and easy sharing of documents.
- Replace Keywords in Paragraphs and Tables: These functions search for specific keywords or placeholders in paragraphs and tables within a Word document and replace them with corresponding data from an Excel spreadsheet.
- Replace Keywords in Word Document: This main function orchestrates the entire process, taking input parameters such as the Word template, Excel file, output folder, and sheet name. It iterates through each row of data in the Excel spreadsheet, replacing keywords in the Word document, and saving the modified document.
import re
from docx import Document
import pandas as pd
import tkinter as tk
from tkinter import filedialog
import threading # Import threading module for concurrent processing
from reportlab.lib.pagesizes import letter
from reportlab.pdfgen import canvas
import docx2pdf
from fuzzywuzzy import fuzz
import string
import PyPDF2
import os
def merge_pdfs(pdf_folder, output_pdf_path):
try:
pdf_merger = PyPDF2.PdfMerger()
# Get all PDF files in the specified folder
pdf_files = [f"{pdf_folder}/{file}" for file in os.listdir(pdf_folder) if file.endswith(".pdf")]
# Add each PDF to the merger
for pdf_file in pdf_files:
pdf_merger.append(pdf_file)
# Write the merged PDF to the specified output path
with open(output_pdf_path, 'wb') as output_pdf:
pdf_merger.write(output_pdf)
print(f"The merged PDF document has been saved to: {output_pdf_path}")
except Exception as e:
print(f"Error in merge_pdfs: {e}")
error_message = f"Error: {str(e)}"
status_label.config(text=error_message)
def preprocess_string(s):
# Remove spaces, dashes, underscores, slashes, and other punctuation
s = re.sub(r'[{}]'.format(re.escape(string.punctuation)), '', s)
return s.replace(' ', '').lower()
# Global variable to signal thread to stop
stop_processing = False
def convert_to_pdf(word_file_path, pdf_file_path):
try:
docx2pdf.convert(word_file_path, pdf_file_path)
print(f"The PDF document has been saved to: {pdf_file_path}")
except Exception as e:
print(f"Error in convert_to_pdf: {e}")
error_message = f"Error: {str(e)}"
status_label.config(text=error_message)
def replace_keywords_in_paragraphs(paragraph, row):
try:
# Find all matches of the pattern in the paragraph text
matches = re.findall(r'«(.*?)»', paragraph.text, flags=re.IGNORECASE)
# Iterate through matches and replace values with Excel data
for match in matches:
# Preprocess both the match and the Excel column name
processed_match = preprocess_string(match)
# Use fuzzy string matching to find the closest match
closest_match, _ = max(((col, fuzz.ratio(processed_match, preprocess_string(col))) for col in row.index), key=lambda x: x[1])
if closest_match and fuzz.ratio(processed_match, preprocess_string(closest_match)) >= 80:
replacement_value = str(row[closest_match])
if replacement_value == 'nan':
replacement_value = ""
paragraph.text = re.sub(fr'«{match}»', replacement_value, paragraph.text, flags=re.IGNORECASE)
except Exception as e:
print(f"Error in replace_keywords_in_paragraphs: {e}")
error_message = f"Error: {str(e)}"
status_label.config(text=error_message)
def replace_keywords_in_tables(table, excel_data):
try:
for row in table.rows:
for cell in row.cells:
# Find all matches of the pattern in the cell text
matches = re.findall(r'«(.*?)»', cell.text, flags=re.IGNORECASE)
# Iterate through matches and replace values with Excel data
for match in matches:
# Preprocess both the match and the Excel column name
processed_match = preprocess_string(match)
# Use fuzzy string matching to find the closest match
closest_match, _ = max(((col, fuzz.ratio(processed_match, preprocess_string(col))) for col in excel_data.index), key=lambda x: x[1])
if closest_match and fuzz.ratio(processed_match, preprocess_string(closest_match)) >= 80:
replacement_value = str(excel_data[closest_match])
if replacement_value == 'nan':
replacement_value = ""
# Replace the pattern with the replacement value
cell.text = re.sub(fr'«{match}»', replacement_value, cell.text, flags=re.IGNORECASE)
except Exception as e:
print(f"Error in replace_keywords_in_tables: {e}")
error_message = f"Error: {str(e)}"
status_label.config(text=error_message)
def replace_keywords_in_word_document(word_template_path, excel_file_path, output_directory, pdf_output_path, sheet_name):
global stop_processing # Use the global variable
# Read the specific sheet from the Excel file
excel_data = pd.read_excel(excel_file_path, sheet_name=sheet_name)
pdf_folder = f"{output_directory}/pdfs"
for _, row in excel_data.iterrows():
if stop_processing:
print("Processing stopped.")
status_label.config(text="Processing stopped.")
break # Exit the loop if stop_processing is True
doc = Document(word_template_path)
# Replace keywords in paragraphs
for paragraph in doc.paragraphs:
replace_keywords_in_paragraphs(paragraph, row)
# Replace keywords in tables
for table in doc.tables:
replace_keywords_in_tables(table, row)
# Extract Loan No from the Excel data
loan_no = str(row['Loan No'])
# Save the modified document to the specified output path
output_filename = f"{output_directory}/{loan_no}.docx"
doc.save(output_filename)
print(f"The modified document has been saved to: {output_filename}")
# Save the modified document as PDF
if pdf_output_path is not None:
output_pdf_filename = f"{pdf_output_path}/{loan_no}.pdf"
convert_to_pdf(output_filename, output_pdf_filename)
print(f"The PDF document has been saved to: {output_pdf_filename}")
# Merge all generated PDFs into a single PDF
if pdf_output_path is not None:
merge_pdfs(pdf_output_path, f"{pdf_output_path}/Full_details_in_one_pdf.pdf")
if not stop_processing:
print("Document processing completed.")
status_label.config(text="Document processing completed.")
def stop_processing_thread():
global stop_processing
stop_processing = True
print("Stopping document processing...")
def browse_excel_file():
filename = filedialog.askopenfilename(filetypes=[("Excel Files", "*.xlsx;*.xls")])
excel_file_entry.delete(0, tk.END)
excel_file_entry.insert(0, filename)
def browse_word_template():
filename = filedialog.askopenfilename(filetypes=[("Word Files", "*.docx")])
word_template_entry.delete(0, tk.END)
word_template_entry.insert(0, filename)
def browse_output_folder():
foldername = filedialog.askdirectory()
output_folder_entry.delete(0, tk.END)
output_folder_entry.insert(0, foldername)
def browse_pdf_output_folder():
foldername = filedialog.askdirectory()
pdf_output_folder_entry.delete(0, tk.END)
pdf_output_folder_entry.insert(0, foldername)
def process_document():
global stop_processing
stop_processing = False
try:
excel_file_path = excel_file_entry.get()
word_template_path = word_template_entry.get()
output_folder_path = output_folder_entry.get()
sheet_name = sheet_name_entry.get()
pdf_output_path = pdf_output_folder_entry.get() if pdf_output_folder_entry.get() else None
if not excel_file_path or not word_template_path or not output_folder_path or not sheet_name:
status_label.config(text="All fields must be filled in.")
raise ValueError("All fields must be filled in.")
# Check if the sheet name exists in the Excel file
excel_data_sheets = pd.ExcelFile(excel_file_path).sheet_names
if sheet_name not in excel_data_sheets:
status_label.config(text=f"Sheet name '{sheet_name}' not found in the Excel file.")
raise ValueError(f"Sheet name '{sheet_name}' not found in the Excel file.")
print("Processing Document...")
status_label.config(text="Processing document...")
processing_thread = threading.Thread(target=replace_keywords_in_word_document, args=(word_template_path, excel_file_path, output_folder_path, pdf_output_path, sheet_name))
processing_thread.start()
#replace_keywords_in_word_document(word_template_path, excel_file_path, output_folder_path, keyword_mapping, sheet_name)
except Exception as e:
print(f"Error in process_document: {e}")
# UI setup
root = tk.Tk()
root.title("Document Modifier")
# Labels
tk.Label(root, text="Select Excel File:").grid(row=0, column=0, padx=5, pady=5, sticky="e")
tk.Label(root, text="Select Word Template:").grid(row=1, column=0, padx=5, pady=5, sticky="e")
tk.Label(root, text="Select Output Folder:").grid(row=2, column=0, padx=5, pady=5, sticky="e")
tk.Label(root, text="Select PDF Output Folder (Optional):").grid(row=3, column=0, padx=5, pady=5, sticky="e")
tk.Label(root, text="Sheet Name:").grid(row=4, column=0, padx=5, pady=5, sticky="e")
# Entry widgets
excel_file_entry = tk.Entry(root, width=50)
word_template_entry = tk.Entry(root, width=50)
output_folder_entry = tk.Entry(root, width=50)
pdf_output_folder_entry = tk.Entry(root, width=50)
sheet_name_entry = tk.Entry(root, width=30)
excel_file_entry.grid(row=0, column=1, padx=5, pady=5)
word_template_entry.grid(row=1, column=1, padx=5, pady=5)
output_folder_entry.grid(row=2, column=1, padx=5, pady=5)
pdf_output_folder_entry.grid(row=3, column=1, padx=5, pady=5)
sheet_name_entry.grid(row=4, column=1, padx=5, pady=5)
# Buttons
tk.Button(root, text="Browse", command=browse_excel_file).grid(row=0, column=2, padx=5, pady=5)
tk.Button(root, text="Browse", command=browse_word_template).grid(row=1, column=2, padx=5, pady=5)
tk.Button(root, text="Browse", command=browse_output_folder).grid(row=2, column=2, padx=5, pady=5)
tk.Button(root, text="Browse", command=browse_pdf_output_folder).grid(row=3, column=2, padx=5, pady=5)
tk.Button(root, text="Process Document", command=process_document).grid(row=5, column=1, pady=10)
# Button to stop processing
tk.Button(root, text="Stop Processing", command=stop_processing_thread).grid(row=5, column=2, padx=10)
# Status label
status_label = tk.Label(root, text="", fg="blue")
status_label.grid(row=6, column=1, pady=5)
root.mainloop()
How to Use the Tool:
Using our Document Modifier Tool is simple:
- Select the Excel file containing your data
- Choose a Word template with placeholders for your data.
- Specify the output folder where the modified documents will be saved.
- Optionally, select a folder for the output PDF documents.
- Enter the name of the sheet containing your data in the Excel file.
- Click “Process Document” to start the modification process.
Screenshots:
- Application Interface

2. Word Document Template

3. Excel containing data that needs to be extracted
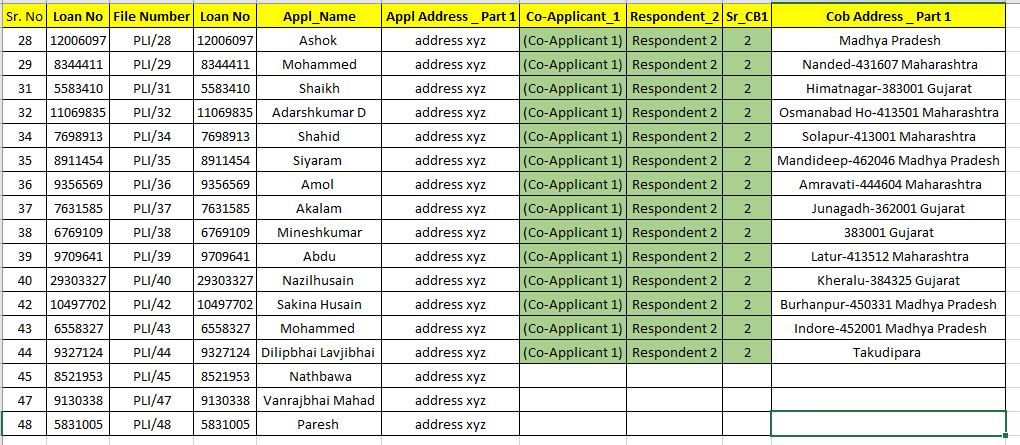
This Excel to Word document modifier will extract the data from an Excel sheet and replace it in a document template, creating separate document files for each record in Excel.
Conclusion:
With Python and the Document Modifier Tool, document management doesn’t have to be a headache anymore. By automating the process of editing and modifying documents, we can save valuable time and resources.
Whether you’re a business professional handling reports or a student managing assignments, this tool can make your life easier. So why wait? Try out our Document Modifier Tool today and experience the efficiency firsthand!